


computer architecture for dummies
what makes a system high performance?


To understand resource efficiency1, you need to have a basic understanding of computer architecture. So: imagine you have a simple calculator.
It can add numbers and store small results. But once you turn it off, it’ll forget whatever you entered. The calculator just needs two things: a CPU (a computing chip) and volatile memory (meaning the memory gets wiped as soon as the calculator turns off).
Some more advanced calculators, like graphing calculators, include persistent storage. They can store variables, settings, and custom functions that the calculator remembers upon being turned on again. On a computer, this is called the disk.
Hard disk drives (HDD) and Solid-state drive (SSD) are both persistent storage devices. HDDs are mechanical and therefore collect wear and tear and slow down with time. SSDs are significantly faster because they don’t have moving parts. They read and write data electronically.
There are two types of volatile memory on a computer. One is the RAM (Random Access Memory) which is smaller, faster, and more expensive than disk space (note how your average laptop has mere gigabytes of RAM but terabytes of storage space). Fetching from RAM instead of disk saves millions of CPU cycles per second.
The other is SRAM, which is even smaller and faster and more expensive and stored on the CPU itself, in caches (L1, L2, L3).
RAM is used for operations that require quick memory access. Applications would be very slow if every process required reading and writing from the disk. The RAM and disk can’t directly communicate with each other, and so rely on the CPU to the middleman.
When the CPU needs something, it checks:
1. cache first (super fast)
2. Then RAM (fast)
3. Then disk (slow)
Caches are the equivalent of keeping frequently used tools right at your workbench instead of walking to the tool shed every time. Applications usually periodically save changes that should persist to their allotted disk space (like the Autosave feature on Word).
This is a pattern you’ll see echoed all across system design - temporarily keeping data you need to look and update often in an easily accessed space. There are often several levels to it too, just like RAM and SRAM.
Great fleas have little fleas upon their backs to bite 'em,
And little fleas have lesser fleas, and so ad infinitum.
— Siphonaptera, Augustus De Morgan
When designing websites, data can be cached to localStorage, sessionStorage, or appStates. Web browsers will cache whole web pages that are frequently accessed. Distributed systems cache database queries close to users.
CPUs and GPUs
One thing every computer needs is a computing chip. It fetches instructions from the RAM, reads data from various places, does math on it, and writes it to other places. On the lowest level, all these instructions are represented as bytes.
There’s more than one kind of computing chip, though. There’s the CPU and the GPU. Most of us don’t know much about them beyond “more cores = more expensive = better.” They tell you if you’re graphics-heavy work, you should invest in a powerful GPU.
But what kind of computations is each one better at? What about when you’re building a software? Why do we benefit from multiple cores?
The CPU is like the master chef in a kitchen. He’s works on one or two complex dishes at a time, but can handle complex recipes, decision-making, and context-switching.
The GPU is like his army of line cooks. Each cook isn’t as flexible, but if you give them the same recipe (like “chop carrots”), they can prep thousands of dishes in parallel, much faster. For example, doing a given operation to every pixel of a video.
Here’s an example of a simple matrix multiplication in Python that would by default be executed on the CPU. The computation is happening sequentially, which is less than ideal.

Here, we use PyTorch to separate it into batches and do it all at once. You can do heavy, repetitive computations 10x to 50x faster this way!

One thing people sometimes forget is that data transfer between CPU and GPU is expensive, so it should be minimized. You can see in the above example that the matrices are created directly on the GPU.
If we were to create them on the CPU and move them over, and keep moving data back and forth to do intermediate steps on different chips, we’d waste all the time we saved moving bytes slowly on the PCLe bus.
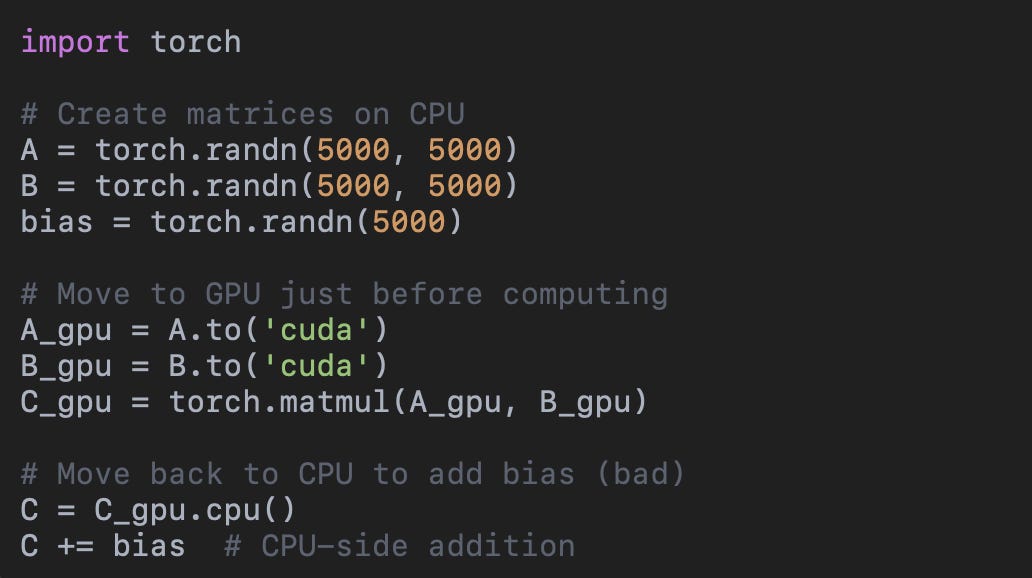
For a slightly more real world example, here’s a good way to slow down deep learning model inference: moving inputs back and forth one by one….

instead of in a batch!

If you’re curious, here are some further technical specs on the CPU vs GPU kindly provided by ChatGPT.

When people say “high performance system” it means a lot of things at once:
low latency (how fast does a single request get a correct response? p99 matters, not just average response time. For example, achieving sub-50ms search results)
high throughput (How many queries/requests/transactions per second can it handle? For example, achieving 100K QPS web search)
horizontal scalability (How well can you add more machines to handle more data/users? For example, adding 10x more users could need ~10x infra or 100x the infra)
fault tolerance (How does the system behave under partial failures like a disk crashing or network partition? For example, implementing graceful failover, replication, retries)
predictable behavior (consistency under varying load: no random slowdowns, no memory leaks over time. For example, no unexplained 10s spikes at midnight)
cost efficiency (Performance per dollar spent. For example, keeping your AWS bill at $1000/month, not $10,000)
resource efficiency (How much CPU, GPU, RAM, disk IO, network is consumed per unit of useful work? For example, a search request uses 1 CPU core for 1 ms, 5MB of RAM, .01MB of disk reads)